De l’analyse de la langue aux modèles génératifs
Publié en ligne le 11 octobre 2023 - Intelligence Artificielle -
Afin de mieux comprendre les forces, mais aussi les limites de systèmes tels que ChatGPT d’Open IA ou Bard de Google, il est nécessaire de comprendre comment ils fonctionnent, sur quels outils informatiques ils reposent. Ces systèmes sont appelés « intelligences artificielles génératives » (ou IA génératives) car ils exploitent des techniques d’intelligence artificielle pour générer du contenu (ici du texte). Ils sont basés sur des modules d’apprentissage automatique issus du domaine du traitement automatique de la langue naturelle (TALN, ou NLP en anglais pour Natural Language Processing).
Le traitement automatique des langues
Les applications du traitement automatique des langues sont entrées dans notre vie quotidienne d’internaute depuis maintenant de très nombreuses années. Analyser grammaticalement une phrase, trouver les synonymes, classer des documents thématiquement, faire des sondages automatiquement sur les réseaux sociaux, répondre à des questions, indexer les ressources textuelles pour que les moteurs de recherche fonctionnent mieux, détecter les entités (personnes, lieux, organisations) sont des exemples de tâches associées à ce domaine.

Bien que liées à des ressources et des savoir-faire communs, ces activités sont traitées chacune de manière spécifique. Une des principales approches mise en œuvre relève du domaine de l’apprentissage automatique (machine learning) et repose sur des algorithmes de prédiction, c’est-à-dire des modèles informatiques capables de suggérer des réponses cohérentes avec les corpus de données qui auront servi lors de la phase d’apprentissage. Ces corpus sont constitués de textes (des phrases, des paragraphes ou des documents longs…) ainsi que des informations associées (l’étiquetage) liées à la tâche que le modèle devra effectuer. Ce peut être par exemple la décomposition grammaticale des phrases, la position des entités ou la classe thématique des documents.
Les textes à traiter sont généralement fournis en entrée au modèle de prédiction sous la forme de descripteurs définis manuellement par des humains. Ces descripteurs combinent des caractéristiques d’analyse linguistiques du texte (longueur, nombre d’occurrences des mots…) à des caractéristiques plus complexes liées au domaine d’application (par exemple, nombre de références liées à un médicament dans le cas d’analyse de textes médicaux).
L’apprentissage de représentation
C’est en 2000 que la notion de « modèle de langue », concept clé dans les IA génératives, est formalisée [1]. Il s’agit de modèles capables de prédire le prochain mot dans une phrase ou un paragraphe. C’est une finalité relativement sans intérêt en soi, mais elle permet d’obtenir des « représentations vectorielles » des mots du texte analysé sans avoir à passer par une définition manuelle des caractéristiques utiles. Chaque mot se verra ainsi lié à un vecteur numérique qui encode la sémantique du mot et ses propriétés grammaticales (voir encadré ci-dessous). C’est ce qu’on appelle l’« apprentissage de représentation » (ou apprentissage des caractéristiques).
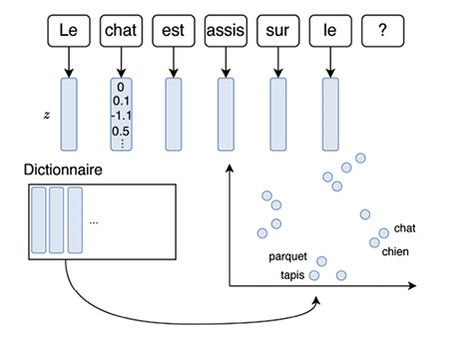
Chaque mot est associé à un vecteur numérique (en bleu) qui correspond à des coordonnées dans un espace sémantique abstrait (à droite, exemple avec un espace sémantique à deux dimensions [z1, z2]). Cette représentation est latente : elle n’a pas de sens intrinsèque mais elle permet de situer les mots les uns par rapport aux autres en regroupant les termes de même sens ou de même classe grammaticale. À la fin du processus d’apprentissage, les mots qui sont très proches dans l’espace sont substituables. Ainsi, considérons la phrase incomplète « Le chat est assis sur le » et supposons que l’on cherche à déterminer le mot manquant. La méthode consiste à tirer parti des représentations numériques des mots pour modéliser le sens général du début de la phrase, sans se focaliser sur le choix spécifique des mots, et aboutir à une proposition pertinente.
Va suivre une succession d’autres avancées significatives entraînant une amélioration des performances dans de nombreuses tâches du traitement automatique de la langue naturelle [2, 3, 4]. Ces avancées vont conduire à un nouveau paradigme d’apprentissage automatique reposant sur plusieurs hypothèses :
- si le modèle hésite entre deux mots dans la prédiction de la suite de la phrase, cela indique que ces termes sont facilement interchangeables (ils peuvent, par exemple, être synonymes) ;
- si deux représentations vectorielles de mots sont proches, ces termes sont sémantiquement reliés ou sont susceptibles d’apparaître dans un même contexte sémantique (par exemple, « rétroviseur » et « volant » peuvent faire référence, parmi leurs diverses significations, au même contexte sémantique, celui de l’automobile) ;
- la prédiction proposée du prochain mot (ou d’un mot intermédiaire masqué dans la phrase) traduit une forme de capture automatique du sens de la phrase. Par exemple, dans la phrase « il fait [MASK], le soleil brille », le mot masqué à prédire est « beau » ;
- générer plusieurs mots l’un après l’autre devrait aboutir à la génération d’une phrase syntaxiquement correcte et sémantiquement non absurde.
Il convient de souligner que l’apprentissage de représentation ainsi décrit a permis des avancées remarquables, non seulement dans le domaine de l’analyse de la langue naturelle, mais également dans ceux de l’image, des systèmes de recommandation ou du traitement du signal.
Représenter le sens des mots
L’analyse des informations textuelles, en particulier des mots, fait référence à une notion centrale en traitement automatique de la langue naturelle : la « sémantique », c’est-à-dire la représentation du sens des mots. Les premiers travaux se sont focalisés sur la constitution d’« ontologies », c’est-à-dire de modèles de données permettant de relier entre eux et organiser différents concepts et ainsi représenter des connaissances complexes [5]. Ainsi, par exemple, un chat est relié au concept d’animal de compagnie, la femelle du chat est la chatte, et l’animal peut être désigné sous divers termes (matou, etc.). Toutefois, ces approches ont vite rencontré des limites du fait de l’importante expertise humaine nécessaire. Des premières tentatives de constructions automatiques d’ontologies sont alors entreprises dans les années 1990 [6].
Mais c’est le paradigme de l’apprentissage de représentation qui va réellement bouleverser la capture de la sémantique avec, en 2013, la mise au point de modèles word2vec [4]. Développés par une équipe de recherche de Google, ils arrivent à construire automatiquement, à partir de données massives issues de Wikipédia, un espace de représentation des mots permettant de les rassembler en fonction de leur proximité sémantique, de mettre en valeur des synonymies et de reconnaître des invariances, c’est-à-dire des relations identiques entre paires de mots distinctes (voir encadré ci-après).
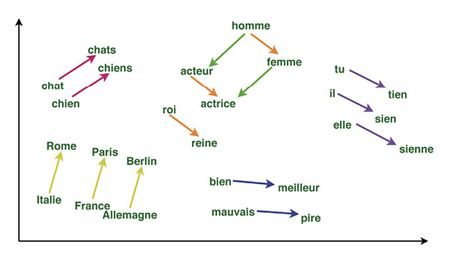
Translation entre pays et capitales, entre adjectif et superlatif, entre féminin et masculin… La première translation mentionnée, par exemple, implique qu’il est possible de retrouver grâce à des opérateurs géométriques dans l’espace de représentation, le pays à partir de la capitale ou l’inverse. L’encodage des mots a donc des propriétés sémantiques et grammaticales très intéressantes, validant ainsi les deux premières hypothèses énoncées dans l’introduction : (1) « si le modèle hésite entre deux mots dans la prédiction de la suite de la phrase, cela indique que ces termes sont facilement interchangeables (ils peuvent, par exemple, être synonymes) » et (2) « si deux représentations vectorielles de mots sont proches, ces termes sont sémantiquement reliés ou sont susceptibles d’apparaître dans un même contexte sémantique ». Par exemple, « chat » et « chien » sont proches dans l’espace, ils sont sémantiquement reliés (ce sont tous les deux des animaux domestiques » et pourraient avoir la même probabilité pour remplacer « ? » dans la phrase suivante « Je souhaiterais avoir un animal domestique, je veux un ? ».
Des mots à la phrase
L’algorithme word2vec a révolutionné les méthodes de construction des représentations des mots. Toutefois, la plupart des tâches du traitement automatique de la langue naturelle se situe au niveau des phrases, des paragraphes ou des documents. Ainsi, la sémantique des mots est une étape nécessaire mais non suffisante.
Une approche très performante à base de « réseaux récurrents » a été proposée en 2014 afin d’aller plus loin dans l’analyse des textes [7]. L’idée a été d’agréger successivement les représentations de mots dans une séquence – via ce qu’on appelle un « encodeur » – pour obtenir une représentation vectorielle de la phrase entière. Cette représentation permettait également la reconstruction de la phrase d’origine à partir d’un « décodeur ».

Ces modèles de type encodeur-décodeur ont été à l’origine d’avancées majeures dans la traduction automatique (DeepL et Google Translate en sont de bons exemples), jusqu’alors basée sur un paradigme de traduction mot à mot. À partir du milieu des années 2010, le principe est désormais de combiner un encodeur dans une langue et un décodeur dans une autre langue, permettant de valider les hypothèses (3) et (4) énoncées en introduction (la prédiction du prochain mot traduit une forme de capture automatique du sens de la phrase et la génération successive de plusieurs mots aboutit à la génération d’une phrase syntaxiquement correcte et sémantiquement non absurde). Le vecteur généré encode bien le contenu du message puisqu’il permet de le regénérer, qui plus est dans n’importe quelle langue. La génération itérative des mots conduit bien à l’obtention d’un message cohérent.
Les hallucinations
Soulignons ici un point fondamental : la génération de texte dans les IA génératives se fait au sens du maximum de vraisemblance, et non selon sa fidélité au contexte du message. Quand le modèle propose un mot, un nom ou une date pour compléter une phrase, son seul critère est la cohérence, en termes de probabilité, du mot avec les représentations faites. Le corollaire de cette conclusion est que le modèle est enclin à générer des « hallucinations », c’est-à-dire des informations vraisemblables (noms de famille, citations de source, date…) mais totalement inventées. Ces informations peuvent donc être factuellement fausses dans le contexte du texte traité. Bon nombre d’utilisateurs de ChatGPT ont pu le constater en posant des questions précises, relatives par exemple à des personnes connues.
Toutefois, il a été constaté que, à architecture égale, l’augmentation de la taille des modèles de langue améliore la mémoire des textes vus, et conduit ainsi à une diminution des hallucinations. Soulignons que les hallucinations ne sont pas le produit d’un apprentissage sur des données imparfaites, mais qu’elles sont bien inhérentes à la méthode. Un apprentissage réalisé uniquement sur des textes scientifiques validés, ou sur Wikipédia, produira également des hallucinations, des erreurs qui ne sont pas présentes dans les données initiales.
Les systèmes actuels
L’état de l’art actuel des IA génératives repose très largement sur le paradigme de l’apprentissage de représentation décrit plus haut. Mais deux nouveautés importantes ont été récemment introduites. L’élément de base modélisé aujourd’hui dans les modèles de langue n’est plus le mot mais le token (groupe de lettres en français) [8]. Par exemple [9], la phrase « J’aime le camembert ! » est décomposée de la façon suivante : [‘▁J’, « ’« , ‘aime’, ‘▁le’, ‘▁ca’, ‘member’, ‘t’, ‘▁ !’]. L’apport principal des tokens est de permettre la modélisation de l’ensemble des mots à partir d’un dictionnaire de taille plus limitée : les groupes de lettres sont extraits statistiquement, il s’agit de motifs fréquents. Ainsi, en choisissant typiquement 30 000 tokens, nous sommes capables de modéliser n’importe quel mot, y compris ceux qui sont très rares ou mal orthographiés et qui étaient ignorés précédemment. Des tentatives de modélisation encore plus universelles (au niveau des lettres) émergent, mais ne sont pas encore suffisamment matures pour s’imposer.
La seconde innovation majeure concerne l’algorithme d’agrégation des tokens. L’architecture Transformer [10] mise au point par une équipe de recherche de Google a très vite été adoptée dans le domaine du traitement automatique de la langue naturelle. Sans entrer dans les détails techniques, retenons que ces nouveaux algorithmes permettent d’apprendre des représentations de mots contextualisées par rapport à une phrase (le mot « vol » n’a pas la même représentation s’il est mentionné dans un contexte d’oiseaux ou de cambrioleurs) via un mécanisme d’attention propre qui estime une importance pour chacun des mots du contexte.
Les Transformers ont été déclinés pour la génération de textes dès leur conception, en particulier pour démontrer leur capacité en traduction automatique ou pour les systèmes de questions-réponses. La génération se fait toujours itérativement, un mot ou un token à la fois en prenant en compte le texte d’entrée (la question ou une phrase dans une langue) ainsi que les mots déjà générés. L’idée est de calculer une « attention croisée » entre la question et les mots ou tokens déjà générés.
L’arrivée de ChatGPT
L’agent conversationnel ChatGPT a été mis à disposition du public en novembre 2022. Le nom ChatGPT est une combinaison des termes « chat » qui signifie « conversation » en anglais, et « GPT » qui est l’acronyme de « Generative Pre-trained Transformer », référence à l’algorithme Transformer évoqué plus haut. ChatGPT possède certaines spécificités.
Alors que les modèles de langue étaient principalement utilisés jusqu’ici comme base pour des systèmes d’analyse de documents (analyse d’opinions, extraction d’entités…), ils deviennent, avec ChatGPT, des objets intrinsèquement interrogeables sur n’importe quel sujet et qui livrent des réponses mot à mot. Ces mots sont choisis selon une loi de probabilité conditionnelle très complexe, issue de la mémoire stockée indirectement dans les paramètres du modèle.
Ouverture au public
Même si cela semble une évidence a posteriori, il est bon de rappeler que la première grande innovation associée à ChatGPT est son ouverture au public. Une version gratuite est disponible en ligne, sur simple inscription. Une version utilisant des algorithmes plus récents est accessible moyennant un abonnement d’environ 20 € par mois. Le fait que de très nombreux utilisateurs se soient saisis de cet outil malgré des défauts évidents a permis de mesurer son apport sur des tâches très variées : développement logiciel, brainstorming, assistant de rédaction de courrier et évidemment réponse à des questions très diverses.
Gigantisme
Comparé aux architectures similaires développées en 2020 par d’autres entités, ChatGPT comporte huit fois plus de modules Transformer, utilise un espace de représentations vectorielles vingt fois plus grand et peut traiter des documents beaucoup plus longs. Au total, il incorpore 175 milliards de paramètres. Cela requiert une taille mémoire d’environ 400 Go pour le modèle et les données à traiter.
Cette taille importante apporte une capacité de mémorisation des textes analysés bien meilleure que les systèmes plus modestes et le nombre d’hallucinations, comme nous l’avons vu, s’en trouve réduit [11].
Comme pour tous les modèles cherchant à prédire le prochain mot, des corpus de plus en plus massifs sont utilisés dans la phase d’apprentissage. Pour ChatGPT, Wikipédia représente seulement 3 % des données d’entraînement.
Capacité de dialogue
L’autre particularité de ChatGPT (aujourd’hui plus largement partagée) est d’offrir des grandes capacités de dialogue. Pour ce faire, un module spécifique a été développé, entraîné sur des données supervisées par des humains qui ont, pour une multitude de requêtes, noté et classé dix réponses proposées par le système, conduisant à des performances de meilleure qualité [12]. Combiné à des réponses construites manuellement, ceci permet à OpenAI d’empêcher que son système réponde à certaines questions (pour des raisons d’éthique, de sécurité, etc.).

ChatGPT sait en outre gérer un dialogue, avec une continuité assurée sur une ou plusieurs répliques.
Les limites des systèmes actuels
Les modèles d’IA générative rencontrent un certain nombre de limites qu’il convient d’analyser. Nous évoquons plus spécifiquement ChatGPT, mais elles sont en général communes à tous les systèmes.
Vérité et vraisemblance
La vérité se réfère à la correspondance entre une déclaration et les faits réels. Une affirmation est considérée comme vraie si elle correspond à la réalité ou à la façon dont les choses sont réellement. Par exemple, si vous demandez à ChatGPT quelle est la capitale de la France et qu’il répond « Paris », cela est vrai car Paris est effectivement la capitale de la France.
La vraisemblance, d’autre part, se réfère à l’apparence de vérité ou de crédibilité d’une déclaration. Une réponse peut sembler plausible ou raisonnable sans nécessairement être factuellement vraie. ChatGPT génère ses réponses en se basant sur des modèles statistiques et des exemples de textes existants. Par conséquent, il peut générer des réponses qui semblent plausibles, mais qui ne sont pas nécessairement vérifiables ou exactes (par exemple, São-Paulo est la capitale du Brésil).
Biais et correction des biais
Des biais de différentes sortes peuvent être présents dans les réponses fournies par ChatGPT. Ils correspondent à la fois à des réalités socioculturelles, mais aussi au miroir déformant des corpus de texte (issus d’Internet) utilisés pour l’entraînement des modèles de langue. Ainsi – et sans réelle surprise –, les utilisateurs ont rapidement montré que le système souffrait des biais habituels observés par ailleurs sur Internet (par exemple, un bon manager est un homme blanc). Ce problème est réel mais commun à tous les systèmes dont l’apprentissage s’effectue sur des données peu ou pas contrôlées.
Se pose alors la question d’étudier dans quelle mesure ces biais peuvent être corrigés. Le contrôle manuel, lors de la phase d’apprentissage, permet au système de répondre à un certain nombre de questions pièges.
Ce contrôle, par un acteur privé qui a ses motivations propres, pose des questions éthiques relatives à la ligne éditoriale des textes proposés en réponse aux requêtes des utilisateurs. Ces choix sont relativement invisibles pour l’utilisateur.
Même si tous les regards sont tournés vers OpenAI pour découvrir les modèles mis à disposition (ChatGPT en novembre 2022, ChatGPT-Plus en mars 2023, GPT4 en avril 2023), les GAMMA (Google, Apple, Meta, Microsoft, Amazon – ex-GAFAM avec Facebook) sont depuis de nombreuses années impliquées dans cette course aux modèles de langue. Bloomberg a récemment annoncé la création d’un modèle de type ChatGPT pour la finance appelé BloombergGPT.
En France, de nombreux chercheurs et laboratoires de recherche travaillent sur l’amélioration des modèles de langue. On note entre autres les premiers modèles de langue pour le français : Camembert [1] (proposé par Fair, Inria et Sorbonne Université) et Flaubert [2] (proposé par les universités Grenoble Alpes, Paris Diderot et PSL).
Le ministère de l’Enseignement supérieur, de la Recherche et de l’Innovation par l’intermédiaire de la société Genci (Grand équipement national de calcul intensif) a acquis un nouveau supercalculateur, installé dans les locaux du CNRS, via son centre national de calcul Idris. Il permet d’exécuter plus de 36 millions de milliards d’opérations par secondes et est utilisé notamment pour des projets d’intelligence artificielle.
La société américaine Hugging Face, créée par trois Français (Clément Delangue, Julien Chaumond et Thomas Wolf), propose une plateforme pour le machine learning (apprentissage automatique) qui héberge modèles, jeux de données et applications web. En collaboration avec plusieurs groupes de recherche en France et à l’international, ils ont créé le projet BigScience pour développer un modèle de langue appelé BLOOM, entraîné sur le super-calculateur Jean Zay et mis à disposition de la communauté. Ce modèle est multilingue et comporte 176 milliards de paramètres.
Références
1 | Martin L et al., “CamemBERT : a tasty French language model”, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, juillet 2020. Sur arxiv.org
2 | Le H et al., “FlauBERT : unsupervised language model pre-training for French”, LREC, 2019. Sur arxiv.org

Stabilité, transparence
Comme la plupart des systèmes de machine learning, les modèles de langue peuvent être vus comme des estimateurs de loi de probabilité particulièrement complexes. Ils sont ainsi capables de réponses justes et précises comme d’erreurs absurdes, voire d’inventions pures et simples. Le tout potentiellement entremêlé. Ces systèmes souffrent en outre d’un manque de transparence et de prédictibilité : il est difficile d’expliquer pourquoi les mots sont tirés et, plus encore, d’anticiper les risques d’erreur du modèle de langue.
Rapport aux sources
Les modèles de langue ont été imaginés au départ comme des étapes préliminaires pour introduire de la connaissance sémantique et grammaticale dans la représentation des mots et des textes, et ainsi réaliser plus efficacement des tâches spécifiques avec d’autres algorithmes. Ces modèles de langue, aujourd’hui interrogés directement, sont utilisés pour leur mémoire et leur capacité à générer des phrases. Dans cet usage, les sources sont absentes : elles ne sont plus utilisées ni même mentionnées. Cela pose non seulement le problème de la vérification des informations générées mais soulève aussi la question du plagiat : comment traiter un ensemble de phrases générées par le système mais en réalité identique à un document vu par le modèle de langue durant l’apprentissage.
Conclusion
Les IA génératives peuvent être des outils puissants et utiles. Elles peuvent également induire en erreur ou servir des intentions malveillantes. Mieux comprendre leur fonctionnement, même si cela nécessite parfois de se plonger dans certains développements techniques, peut permettre à tout un chacun de devenir un utilisateur mieux averti.
Précisons enfin que les IA génératives constituent un domaine qui évolue extrêmement rapidement. Les nouvelles versions à venir pourraient nous surprendre et résoudre certains des problèmes décrits ici, et aussi en soulever d’autres.
Et si vous avez été impressionnés par ChatGPT, pour continuer à vous bluffer, saurez-vous trouver le paragraphe de cet article écrit par ce logiciel ? Nous vous rassurons, nous avons soigneusement vérifié la véracité des informations générées !
1 | Bengio Y et al., « A neural probabilistic language model”, Advances in Neural Information Processing Systems, 13, 2000.
2 | Keller M, Bengio S, “A neural network for text representation”, in Artificial neural networks : formal models and their applications, 2005, EPFL Scientific Publications, 667-72. Sur infoscience.eplf.ch
3 | Collobert R, Weston J, “A unified architecture for natural language processing : deep neural networks with multitask learning”, Proceedings of the 25th international conference on machine learning, 2008, 160-7. Sur machinelearfning.org
4 | Mikolov T et al., “Distributed representations of words and phrases and their compositionality”, Advances in neural information processing systems, 2013. Sur arxiv.org
5 | Miller GA, “WordNet : a lexical database for English”, Communications of the ACM, 1995, 38 :39-41.
6 | Deerwester S et al., “Indexing by latent semantic analysis”, Journal of the American society for information science, 1990, 41 :391-407.
7 | Sutskever I et al., « Sequence to sequence learning with neural networks”, Advances in neural information processing systems, 2014. Sur arxiv.org
8 | Bojanowski P et al., “Enriching word vectors with subword information”, Transactions of the Association for Computational Linguistics, 2017, 5 :135-46.
9 | Hugging Face, “CamemBERT : a tasty French language model, base”, fichier open source. Sur huggingface.co
10 | Vaswani A et al., “Attention is all you need”, Advances in neural information processing systems, 2017. Sur arxiv.org
11 | Brown TB et al., “Language models are few-shot learners”, 2020. Sur arxiv.org
12 | Ouyang L, “Training language models to follow instructions with human feedback”, Advances in Neural Information Processing Systems, 2022, 35 :27730-44.
ChatGPT, c’est un million d’utilisateurs sur les cinq premiers jours de lancement (à noter que Facebook et Netflix ont respectivement attendu 10 mois et 3,5 ans pour atteindre ce nombre d’utilisateurs). En mars 2023, on comptait 1.16 millions d’utilisateurs pour 25 millions de visites par jour [1, 2].
Mais ce n’est pas gratuit….
Le modèle comporte 175 milliards de paramètres. Il a été entraîné avec une base de 300 milliards de mots inclus dans un corpus de texte de 570 gigabits. Un serveur de calcul de plus de 10 000 GPU (cartes graphiques) a été utilisé (correspondant environ à un « data center » d’une superficie d’environ 80 m2). Le coût total de l’entraînement est estimé à 12 millions de dollars.
Le coût d’annotation des données est également important (trois contrats de 200 000 dollars) et a fait également polémique dans la presse [3]. Ces contrats ont permis d’engager des Kényans pour travailler 9 heures par jour au tarif de 2 $ l’heure pour détecter des textes « toxiques » (violence, discours haineux et abus sexuels).
Même si l’utilisation de ChatGPT demande moins de ressources de calcul que l’entraînement du modèle, cela reste toutefois très impressionnant : on estime à 700 000 dollars le coût journalier de fonctionnement des serveurs informatiques [4].
ChatGPT dispose d’une version gratuite et d’une version payante. Les revenus attendus sont de l’ordre de 200 millions de dollars pour fin 2023 et d’un milliard de dollars pour fin 2024 [1]. À ce jour, l’entreprise Open-AI est valorisée autour de 29 milliards de dollars et a reçu en janvier 2023 10 milliards d’investissement de la part de Microsoft.
Références
1 | Saidane N, « Quel est le nombre d’utilisateurs ChatGPT ? : chiffres clés », L’entrepreneur en vous, 24 mars 2023. Sur lentrepreneurenvous.com
2 | Growth Hacks, « ChatGPT : statistiques et chiffres clés », blog, 2023. Sur sales-hacking.com
3 | “Exclusive : OpenAI used Kenyan workers on less than $2 per hour to make ChatGPT less toxic”, Time, janvier 2023. Sur time.com
4 | « Argent, eau, énergie… combien coûte ChatGPT ? : le vrai prix fou de la révolution IA », lebigdata, avril 2023.
Sur lebigdata.fr
Publié dans le n° 345 de la revue

Partager cet article




Les auteurs

Laure Soulier
Maître de conférences à l’Institut des systèmes intelligents et de robotique, Sorbonne Université.
Plus d'informations
Intelligence Artificielle
L’intelligence artificielle (IA) suscite curiosité, enthousiasme et inquiétude. Elle est présente dans d’innombrables applications, ses prouesses font régulièrement la une des journaux. Dans le même temps, des déclarations médiatisées mettent en garde contre des machines qui pourraient prendre le pouvoir et menacer la place de l’Homme ou, a minima, porter atteinte à certaines de nos libertés. Les performances impressionnantes observées aujourd’hui sont-elles annonciatrices de comportements qui vont vite nous échapper ?
Intelligence artificielle
Le 16 août 2020
IA génératives : une révolution en cours ?
Le 17 octobre 2023
De l’analyse de la langue aux modèles génératifs
Le 11 octobre 2023
Les systèmes d’intelligence artificielle pour la génération d’images
Le 5 octobre 2023
IA génératives : un risque accru de désinformation ?
Le 29 septembre 2023